Text Hoarder
Chrome Extension: save articles & see reading stats
Developed in
Text Hoarder is a browser extension for Google Chrome that provides reader view, saving articles for later, and generation of stats based on your reading habits.
Main features:
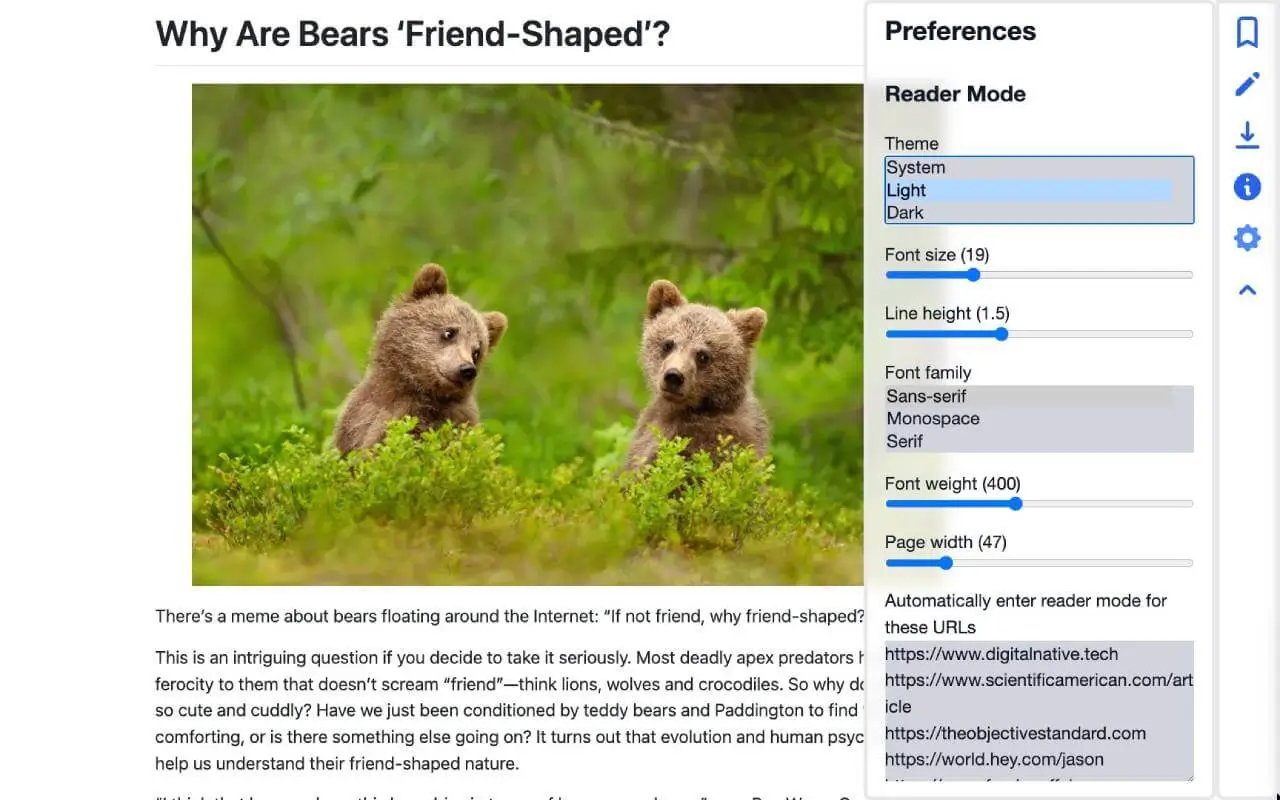
Customizable reader mode
Bypass flashing ads, distracting elements, scrolljacking and other inconveniences of modern day web browsing.
Improve accessibility & usability of any webpage
Automatically enter reader mode for configured webpages
Download simplified page as HTML, markdown or plain text
Print simplified page or convert it to PDF using browser's print dialog
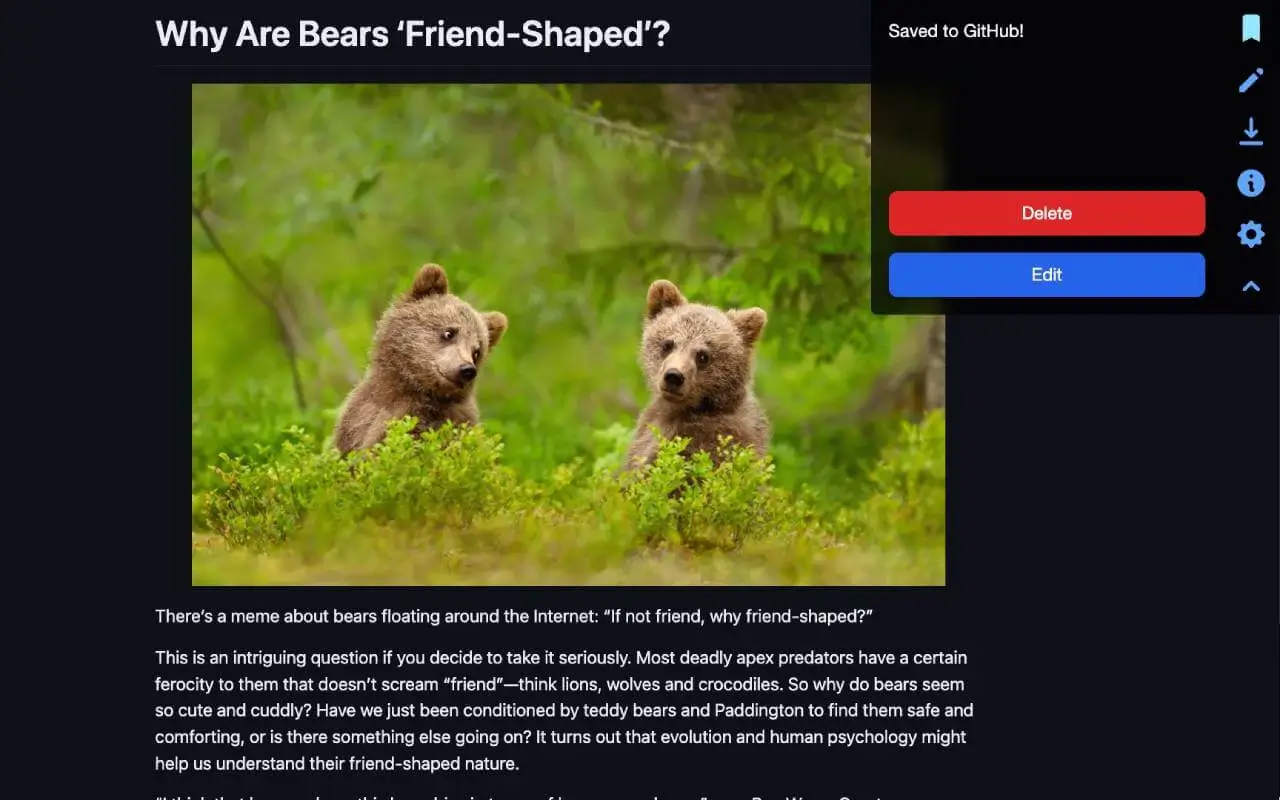
Save articles to a private GitHub repository as Markdown files
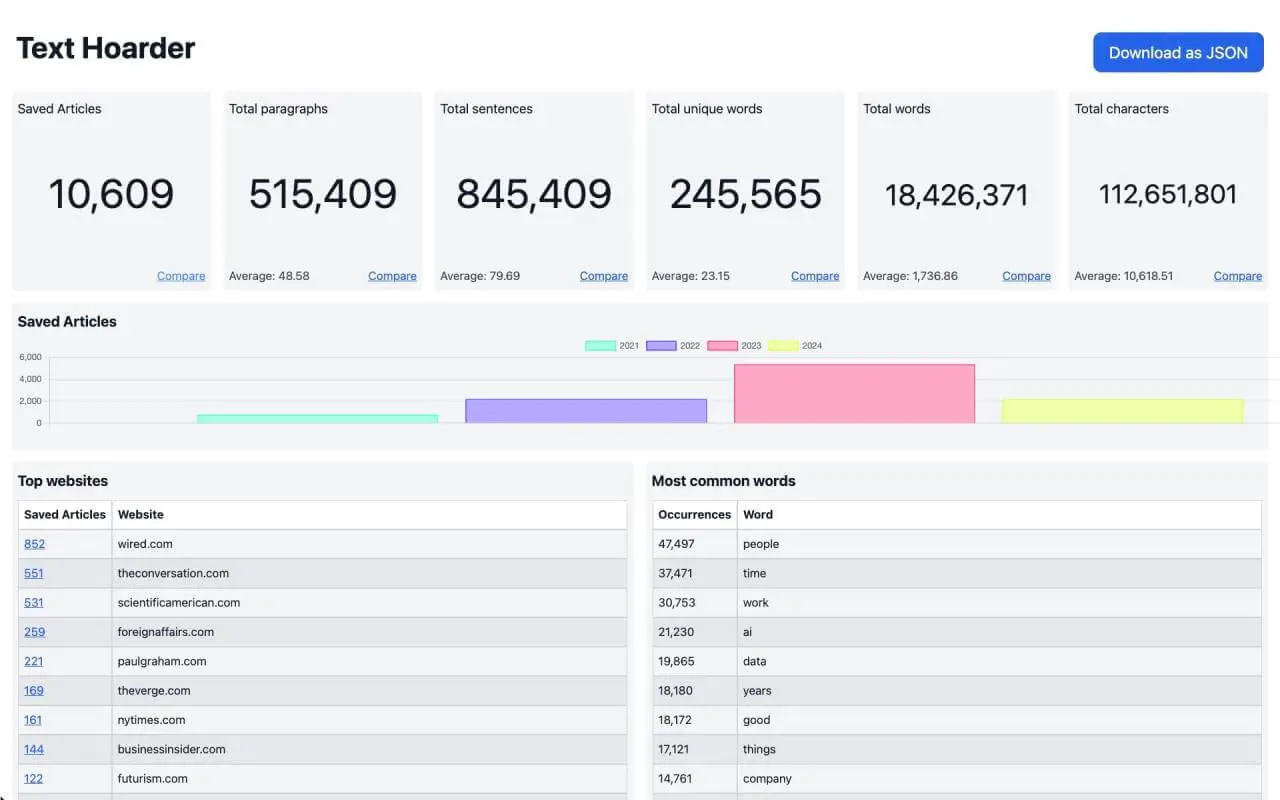
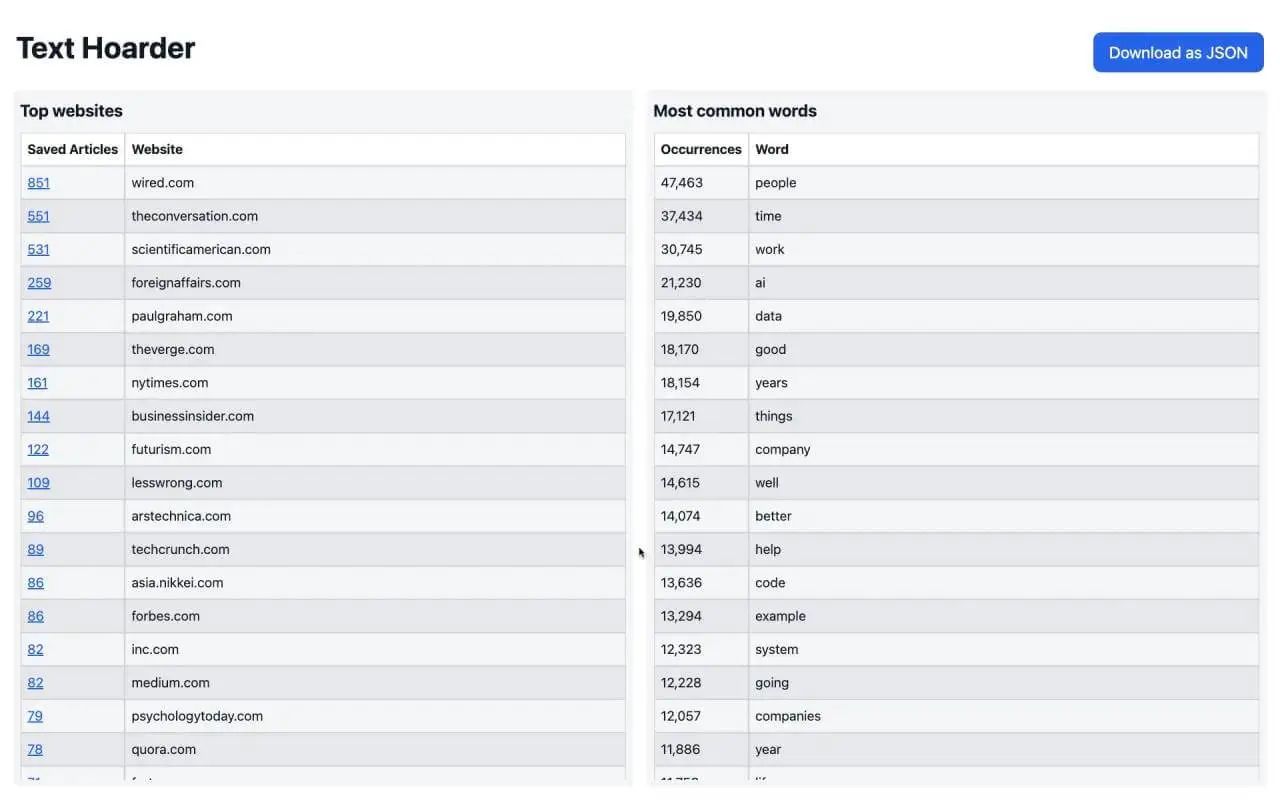
Generate stats based on saved articles to see your reading habits (most common websites, popular topics, count of articles saved per year)
Cleanup saved articles for use with any text-to-speech software
Screenshots

Motivation
The extension's main feature is a reader mode. There are many "reader mode" extensions in the Google Web Store.
This one has two core differentiators:
Made with the Unix philosophy. The extension saves articles directly to your GitHub repository - you can check it out locally, and open it in VS Code, Obsidian or any other tool of choice! You can manipulate or backup the data at will. There is even a CLI that can generate extensive stats based on your saved articles
Made for those who like a more accessible and usable web. Bypasses scrolljacking, flashing ads, broken styles. The extension has great screen reader and keyboard accessibility support
The tricky parts
To keep the extension more user friendly, I initially wanted to generate the
stats in the browser extension, without the need for a CLI utility. This proved
tricky. GitHub provides an API for downloading the entire repository as a
.tar.gz or .zip file, and such file can be extracted in-browser - however,
that is not sufficient.
As part of the stats generation, I need access to file creation date and what Git tag is the file part of, which that endpoint did not provide. One could request each repository's file one by one and get the necessary metadata, but the number of API requests that would involve is impractical (I have almost 11,000 articles saved in my private text-hoarder-store repository). Thus, a CLI was required, to be able to checkout the repository locally and run Git commands on it.
Keeping the extension open and unopinionated was a bit of a challenge too. The extension needs to save files to a user's GitHub repository in a way that is easy to understand and manipulate (I settled on the "<year>/<domain>/<rest of the url>" naming convention). Converting a URL to a file path was a bit tricky too - many characters are restricted from file names on macOS and Windows. Windows also has a max file path length limitation. Also, the extension has to be careful not to overwrite any user files, and be friendly with any edits the user made locally.
Unexpectedly, many articles have query string parameters or even hash parts that are significant for loading the correct content - the extension needs to be smart about cleaning up UTM trackers and other noise from the URL, without breaking the reference to the original content.
Related projects
See also my Calendar Plus and Goodreads Stats browser extensions