Small Retail Management
Track retail revenue, expenses, and salaries
Developed in
A simple-to-use dashboard for tracking revenue, expenses, and salaries for every employee of your small business. Gain insights, see trends, and make informed decisions.
Features
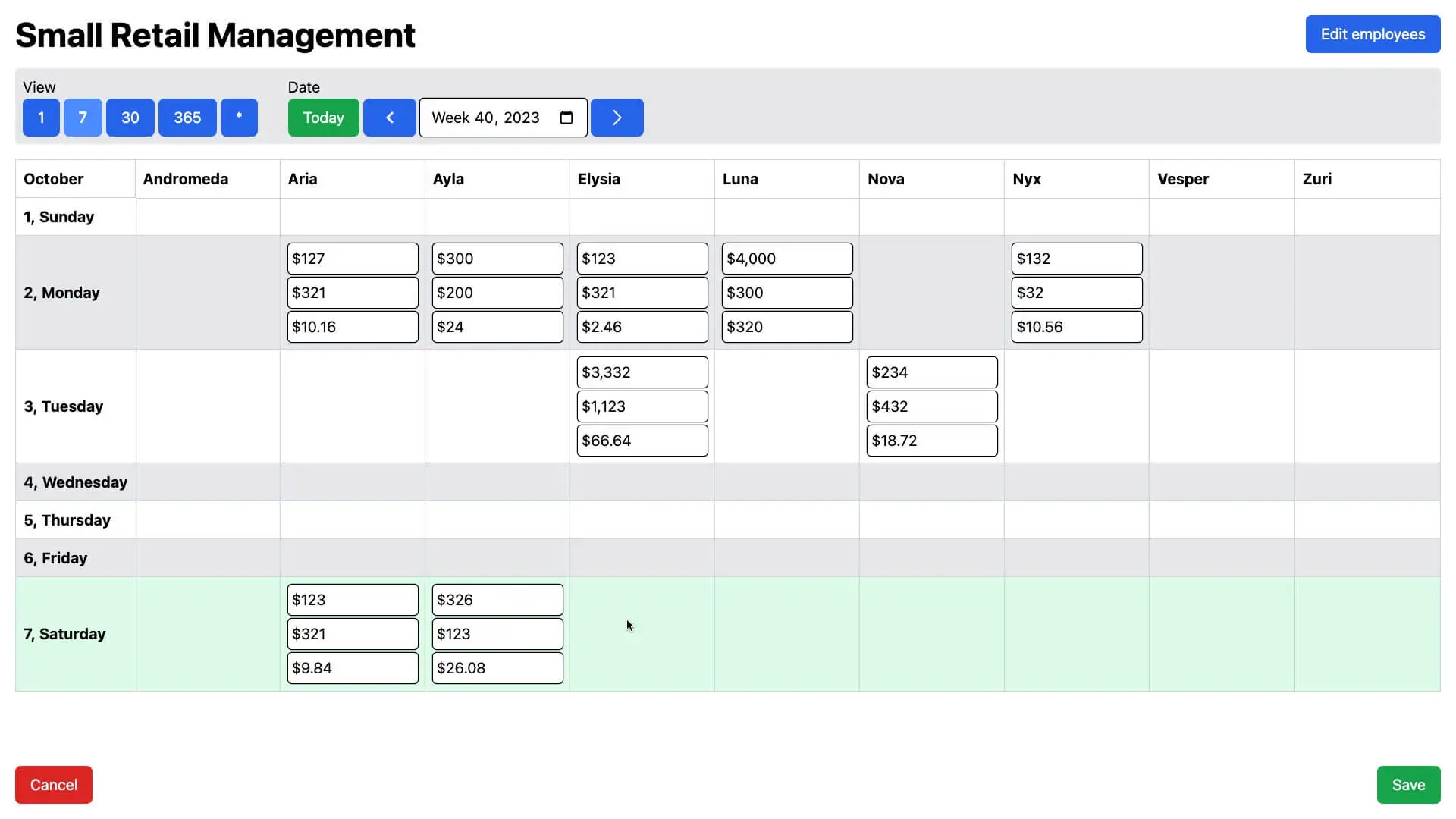
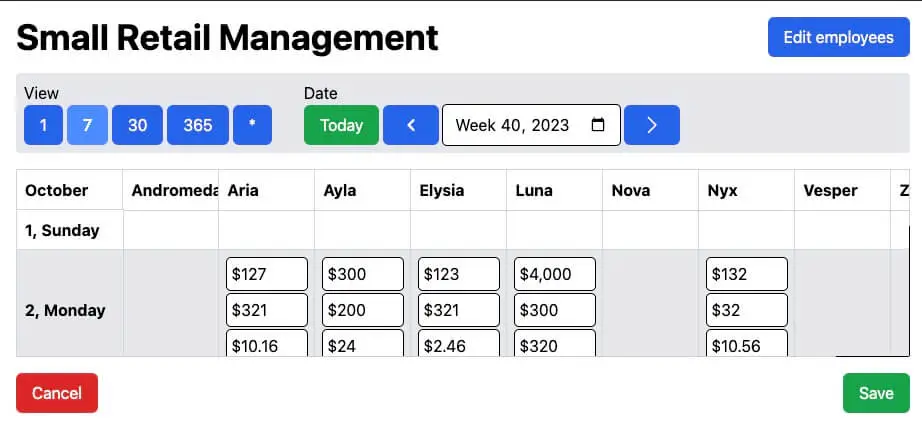
Conveniently enter data for the day or entire week from your phone or desktop
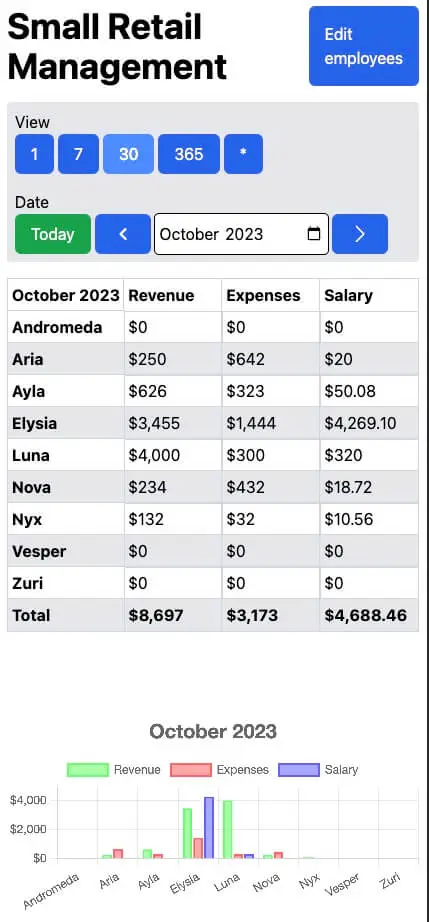
See total revenue, expenses, and salary for each employee for the month, year, or all time.
Add employees, set revenue share percentage and base salary - total salary will be calculated automatically
Easily jump between dates to see historical data
Video overview
Screenshots

Technologies used
Firebase Firestore Database
Firebase Authentication
JavaScript
TypeScript
React
Next.js
Tailwind CSS
Motivation
My parents tried a sophisticated solution for tracking revenue and expenses - it included barcode support, reports & labels, inventory management, permission system...
While that worked for a large shop, it was too much overhead for their smaller shops. Thus, in 2018 I created a predecessor to this project - 1c-clone. It was written in PHP and MySQL in one continuous 9-hour coding session. Consequently, code quality wasn't the best (everything was in a single 2600 line file) and mobile support wasn't great.
Still, it was enough for my parents' needs. However, I gradually deprecated or rewrote all of my PHP projects, and this was the only one left running - in order not to rent an entire server just for one small project, I decided to rewrite it, and in the process show off what I have learned over the last 5 years.
At the same time, the core design principle through this project was simplicity - fewer features, bigger buttons, clearer pages, more white space - resulting in a friendly looking application that does just what it was designed to do, and nothing more.
Reflection
Current implementation has half the features of the previous PHP version, while being almost twice as large line-count wise, and using 19 more external dependencies (3 vs 22). While I could say that greater code quality, better accessibility, mobile support and other nice things are the cause of it, I still can't escape the conclusion that the way we write even small projects today is overly bloated compared to the way it was in the past.
Things learned
Firestore
I worked with Firebase a bit in the past, but this project really allowed me to explore its features in more depth.
In the process, I learned how Firestore is immensely scalable, while being focused on performance, low-latency and offline capability. All very impressive things.
However, this project would have an average concurrent user count of 1, with latency being non-critical, and online access being almost guaranteed. At the same time, the scalability goals of Firebase meant that things I am used to in MySQL like GROUP BY operation with SUM, or JOINs across tables are not available. Instead, the recommended solution is to maintain your own counters in a separate table - that added complexity and potential bugs. Additionally, Firestore's pursuit of low-latency means very strict limits - for example, a transaction can't have more than 20 operations. Finally, there is no strict schema, unless you choose to enforce one using security rules, leading to more potential bugs/extra overhead.
At the end, I realized that Firestore is not a good fit for the needs of this project, and something like Postgres or Amazon DynamoDB would have worked better. In the future, I will spend more time researching available options and evaluating whether they are good fit, rather than just picking up what seems most familiar/came to my mind first.
Minimalism
While I love simplicity and minimalism, in practice, following these guiding principles can be hard. There is always the temptation to add one more feature just in case, or to add another layer of abstraction. Given that I knew clearly what features my parents would need, it was easier to justify not overengineering the solution. Still, it is wise to reflect on this and keep minimalism in mind for future projects.